理论#
Retrieval Augmented Generation(检索增强生成) 从一个小白的角度,从理论出发,一起构建一个MVP RAG 系统,最近以实战结尾,让我们一起踏进 RAG 的大门。
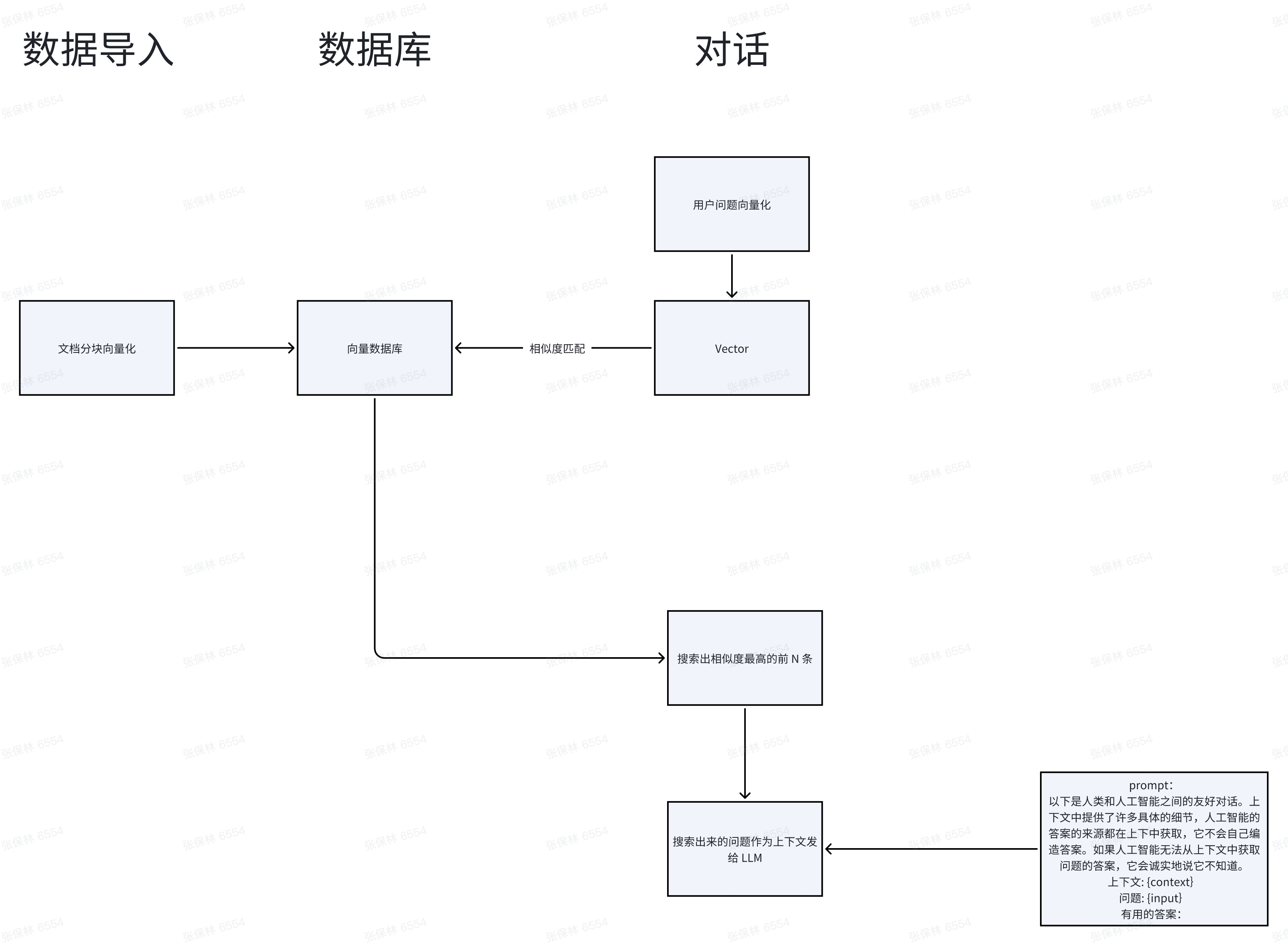
检索流程#
简易版:
什么是向量#
向量是 RAG 中数据召回的基础,我们以狗🐶举例,来一起认识下,什么是向量?
 我们之所以能够分辨不同的狗,是因为我们会从不同的角度来观察它的特征。
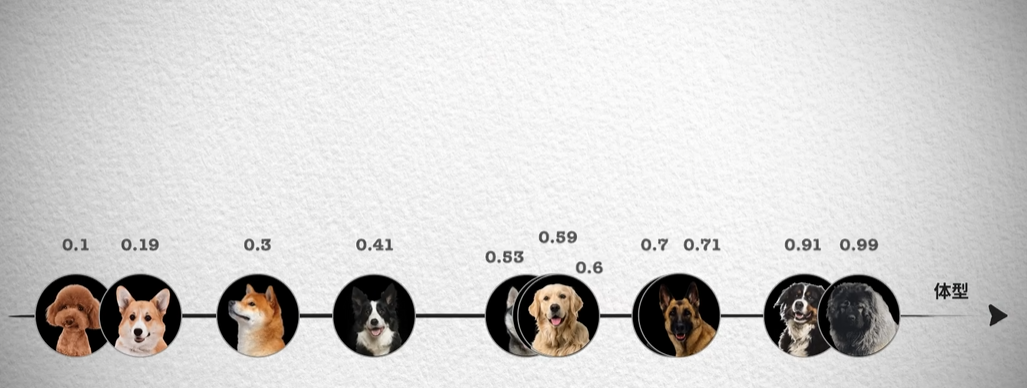
以体型为数据,我们先从一维的角度来分析:
我们之所以能够分辨不同的狗,是因为我们会从不同的角度来观察它的特征。
以体型为数据,我们先从一维的角度来分析:
 此时,有一些种类是重叠的,此时我们加一个维度:毛长
此时,有一些种类是重叠的,此时我们加一个维度:毛长
 在物理世界中,我们往往以三维坐标轴来标记数据。
在向量中,维度可以达到上千维。openai 的text-embedding-3-large则为 3072。
只要我们不断添加维度,不同的物体,就能清晰的区分开。
在物理世界中,我们往往以三维坐标轴来标记数据。
在向量中,维度可以达到上千维。openai 的text-embedding-3-large则为 3072。
只要我们不断添加维度,不同的物体,就能清晰的区分开。
 同样,同类物体就会聚在一起
同样,同类物体就会聚在一起
 拿到这些数据后,怎么计算两个向量的距离呢?
拿到这些数据后,怎么计算两个向量的距离呢?
相似性测量#
欧几里得距离#
欧几里得距离算法的优点是可以反映向量的绝对距离,适用于需要考虑向量长度的相似性计算。例如推荐系统中,需要根据用户的历史行为来推荐相似的商品,这时就需要考虑用户的历史行为的数量,而不仅仅是用户的历史行为的相似度。
余弦相似度#
余弦相似度对向量的长度不敏感,只关注向量的方向,因此适用于高维向量的相似性计算。 例如语义搜索和文档分类。
点积相似度#
点积相似度算法的优点在于它简单易懂,计算速度快,并且兼顾了向量的长度和方向。它适用于许多实际场景,例如图像识别、语义搜索和文档分类等。但点积相似度算法对向量的长度敏感,因此在计算高维向量的相似性时可能会出现问题。
在大多数语义搜索和文档分类任务中,余弦相似度通常是更好的选择。
实战#
MVP#
import { Configuration, OpenAIApi } from 'openai'import * as cosineSimilarity from 'cosine-similarity'
// 配置OpenAI APIconst configuration = new Configuration({ apiKey: process.env.OPENAI_API_KEY,})
const openai = new OpenAIApi(configuration)
// 使用 OpenAI 的 text-embedding-3-large 模型来将文本转为向量async function getEmbedding(text: string): Promise<number[]> { const response = await openai.createEmbedding({ model: 'text-embedding-3-large', input: text, })
const embedding = response.data.data[0].embedding return embedding}
// 计算两个向量的余弦相似度function calculateCosineSimilarity(vec1: number[], vec2: number[]): number { return cosineSimilarity(vec1, vec2)}
// 将多个文本转换为向量并存储async function embedTexts(texts: string[]): Promise<number[][]> { const embeddings = [] for (const text of texts) { const embedding = await getEmbedding(text) embeddings.push(embedding) } return embeddings}
// 获取与问题最相似的前10条文本资料async function findTopMatches( question: string, texts: string[], embeddings: number[][]): Promise<string[]> { const questionEmbedding = await getEmbedding(question)
const similarities = embeddings.map((embedding, index) => ({ text: texts[index], similarity: calculateCosineSimilarity(questionEmbedding, embedding), }))
// 按相似度排序并返回前10个 similarities.sort((a, b) => b.similarity - a.similarity)
return similarities.slice(0, 10).map((item) => item.text)}
// 主逻辑:将用户问题与文本资料匹配async function handleUserQuestion( question: string, texts: string[]): Promise<string[]> { const embeddings = await embedTexts(texts) return await findTopMatches(question, texts, embeddings)}
// 示例使用;(async () => { const texts = [ '这是关于人工智能的资料。', '这是关于机器学习的资料。', '这是关于自然语言处理的资料。', ]
const question = '什么是人工智能?' const matches = await handleUserQuestion(question, texts)
console.log('匹配到的文本资料:', matches)})()这样一个最小的 demo 就跑通了,再实际生产中还要配合数据库存储。作为 jser,推荐一些 js 相关技术栈:
- Nestjs
- ORM: Prisma, orm 中最早支持向量类型,且社区活跃度高
- 向量数据库:PostgreSQL + PgVector,为数不多的(非)关系数据库支持向量存储的,且性能和社区活跃度都可以。当然你也可以用一些专门做向量的数据库方案:Pinecone、Milvus … MVP: https://github.com/dvlin-dev/rag-copilot/blob/main/server/src/modules/vector/vector.service.ts
优化方向#
从 chunk 角度#
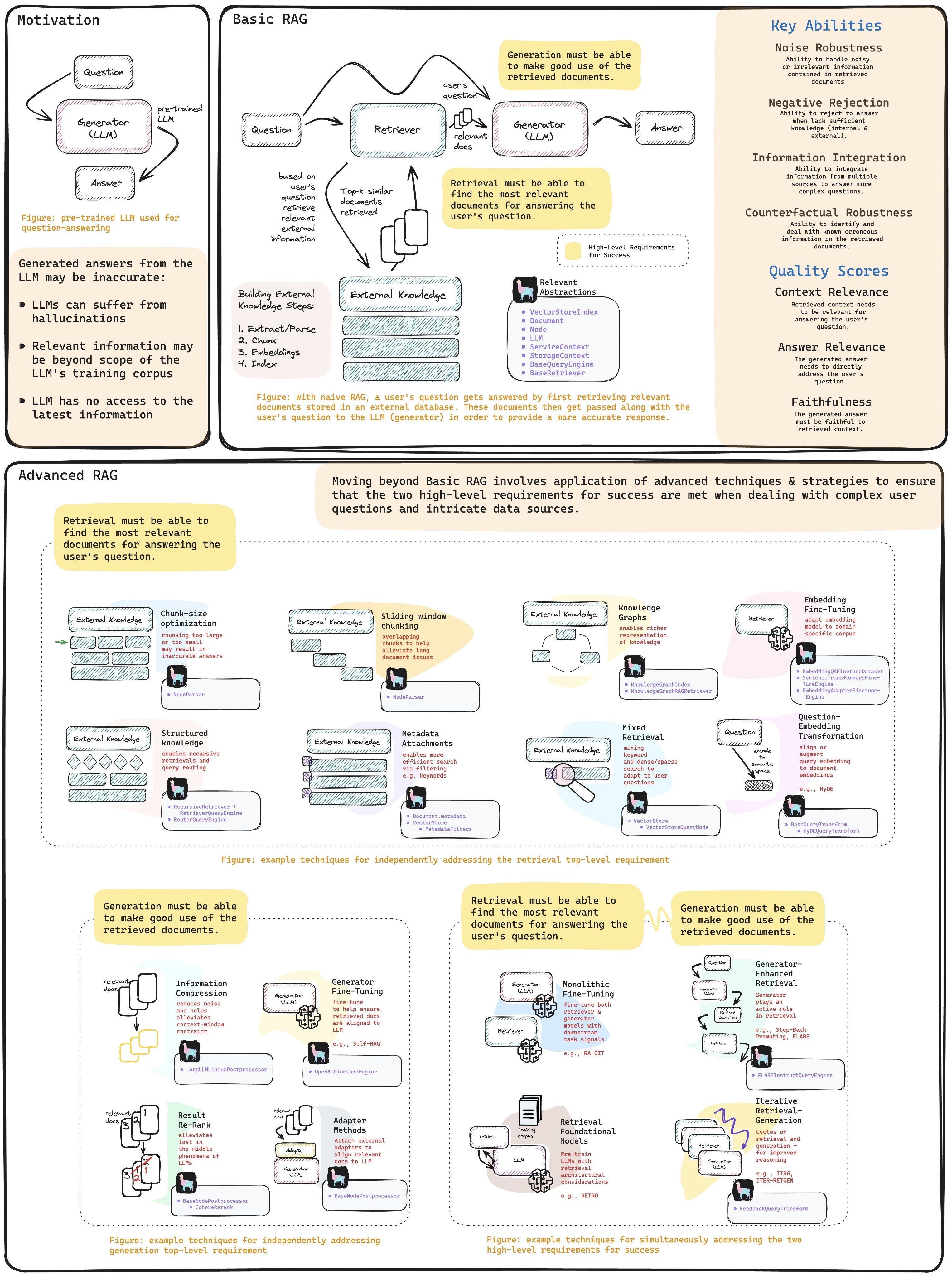
混合查询#
claude 上下文检索融合方案
「embedding + 词汇匹配」召回内容后,重新排名去重。以提高召回准确率。具体操作如下:

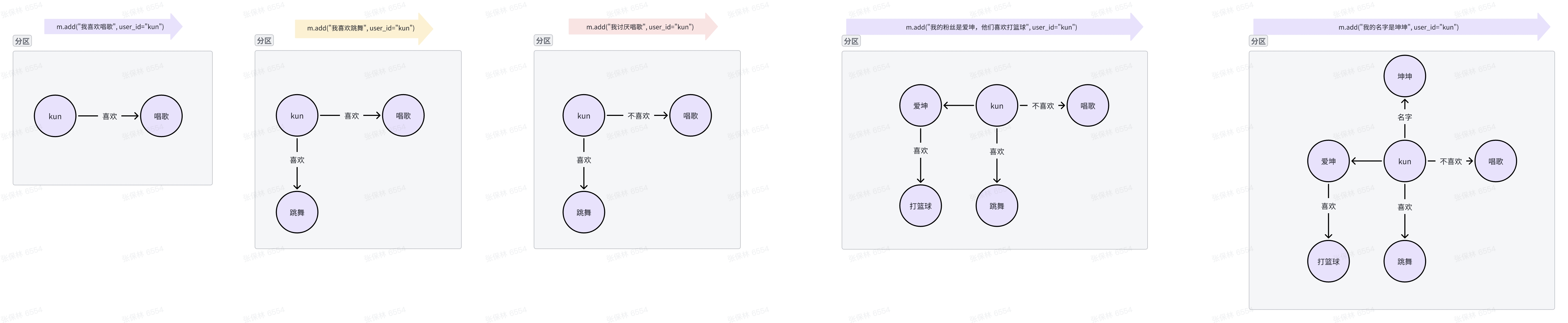
GraphRAG#
不同于向量 Embedding 的形式,Graph 对于结构复杂、经常改动的数据更友好
应用#
- 文档检索: https://www.mendable.ai/
- 个人助理: https://app.me.bot/
- 智能客服
- 各种工作流 …
参考资料#
推荐阅读以下资料,都是系统性的讲解
- 【上集】向量数据库技术鉴赏
- 【下集】向量数据库技术鉴赏,https://www.bilibili.com/video/BV1BM4y177Dk/?spm_id_from=333.788.recommend_more_video.-1&vd_source=8cbf3df49bc9bd05e33e78a3420ceca6%5D
- 基于大语言模型构建知识问答系统, https://zhuanlan.zhihu.com/p/627655485
- LLM+Embedding构建问答系统的局限性及优化方案, https://zhuanlan.zhihu.com/p/641132245
- https://twitter.com/Tisoga/status/1731478506465636749?s=20
- https://twitter.com/dotey/status/1743393585217556991
- https://github.com/microsoft/graphrag
- https://docs.mem0.ai/open-source/graph_memory/overview
- https://x.com/llama_index/status/1796936357966954564
- https://github.com/dvlin-dev/rag-copilot
- https://www.anthropic.com/news/contextual-retrieval